Automatically Generating Grasps with QD
Why Grasping should meet QD
Grasping is subject to strong interest from both the AI and the robotics communities as it is a prerequisite to many manipulation tasks (Hodson, 2018). But this hard exploration problem is still partially solved: learning policies with generalization capabilities would require large and high-quality datasets.
Quality-Diversity (QD) optimization is a branch of evolutionary algorithms that aims to find a set of diverse and high-performing solutions to a given problem. Recent works have exploited the exploration capabilities of those algorithms to produce datasets for policy learning (Morrison et al., 2020)(Macé et al. 2023).
Inspired by these examples, the present work aims to leverage QD to generate large datasets of diverse and high-performing grasping trajectories. Investigating this problem raises many questions that any QD practitioner faces when addressing a new problem with these algorithms: how to adapt the QD framework to the targeted task? What QD methods are the most likely to be efficient on that task? On what metrics should one rely to compare them?
Among all the raised challenges, the definition of the behavioral characterization is one of the most critical matter to get the most out of QD method on a new targeted problem.
Behavioral Characterization for Grasping
The behavioral characterization is at the core of QD algorithms: defining the right behavior space is thus critical to address grasping.
One can distinguish two main usage of in QD methods. In some works, the behavior space
is used to find solutions to a hard exploration problem (driving
). This is mostly found in studies derivating from the vanilla Novelty-Search paper ( et al), in which
is used as a proxy to avoid local minima due to sparse or deceptive reward signal. In other works,
is used to distinguish solutions for a given targeted task (describing
). These studies are usually based on the vanilla MAP-Elites method (Mouret et al, 2015), in which the behavioral characterization allows to maintain diverse solutions throughout the search thanks to a local competition mechanism.
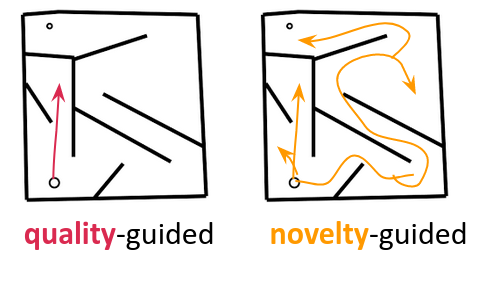
As grasping is a hard exploration problem, a good driving is required. However, generating large and diverse grasping datasets requires defining what diverse grasping means. For that reason a good describing
is also required. The first paper that addressed grasping with QD methods proposed to rely on multiple behavior descriptors to circumvent this problem (Morel et al, 2022). But this approach raised many challenges: How to explore several behavioral spaces efficiently? How to design or learn the most relevant driving or describing
? More importantly, how to compare QD methods on the obtained results, and how to interpret the output of the algorithm?
This work argues that grasping can be addressed with QD methods by operating on a single behavior space , defined as follow:
where is the Cartesian position of the end effector when touching the object for the first time. Such a behavioral characterization has many benefits: it keeps
in low dimensions, it consists of a single behavior space, it is a good driving
(as an object must be touched to grasp it), it is a good describing
(as the goal is to distinguish grasps from the position in which the end effector interacts with the object), and it makes the outcome easily interpretable and visualizable.
This characterization has however a major drawback: if the attempted trajectory does not make the gripper touch the object, the behavior descriptor is not defined. It makes the problem fall in a sparse interaction setup, in which the evolutionary process cannot always rely on a behavioral signal to optimize its running solutions.
What is the best QD algorithm for Grasping?
To identify the best method for addressing grasping, about 15 QD algorithms and related variants have been compared on grasping domains. Among them can be distinguished what should be the most promising methods:
• NSMBS: the only QD method in the literature that is explicitly designed to address grasping (Morel et al, 2022);
• SERENE: state-of-the-art QD method that specifically focus on sparse reward domains (Paolo et al, 2021);
• CMA-MAE: state-of-the-art QD method that showed robustness to domains submitted to flat fitness landscape (Fontaine and Nikolaidis, 2023).
Note that NSMBS and SERENE rely on a Novelty Search backbone, while CMA-MAE relies on a MAP-Elites backbone. These methods do not use the same structure of container – the archive of previously found behavior that acts as a memory to guide the QD optimization process. NSMBS and SERENE use unstructured archives, while CMA-MAE uses a structured archive. Such a difference prevents easy comparison, as one cannot consider the container as the output of the algorithms to compute key metrics.
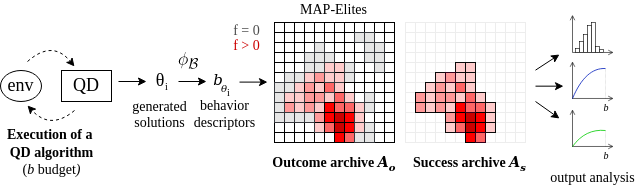
To allow fair comparisons, an evaluation framework that distinguishes the outcome of the algorithm from its internal component has been proposed. Each QD method is considered as a black box that produces individuals. All individuals ever produced are considered for being added into an outcome archive, that consists of a standard MAP-Elites. The set of solutions from the grid that got a non-null fitness (i.e. successful grasps) is called the success archive, and is the targeted outcome of the QD methods for this study.
Measuring the task sparsity
Experiments have been conducted on the simulator PyBullet. It consists of a robotic manipulator that must grasp a targeted object on a table. Supported grippers include a parallel gripper and a dexterous hand.

As discussed above, the definition of make the problem fall into a sparse interaction setup. To measure to what extent the targeted domains are submitted to those problems, a large set of solutions was randomly sampled from the parameters space and evaluated on the domain.
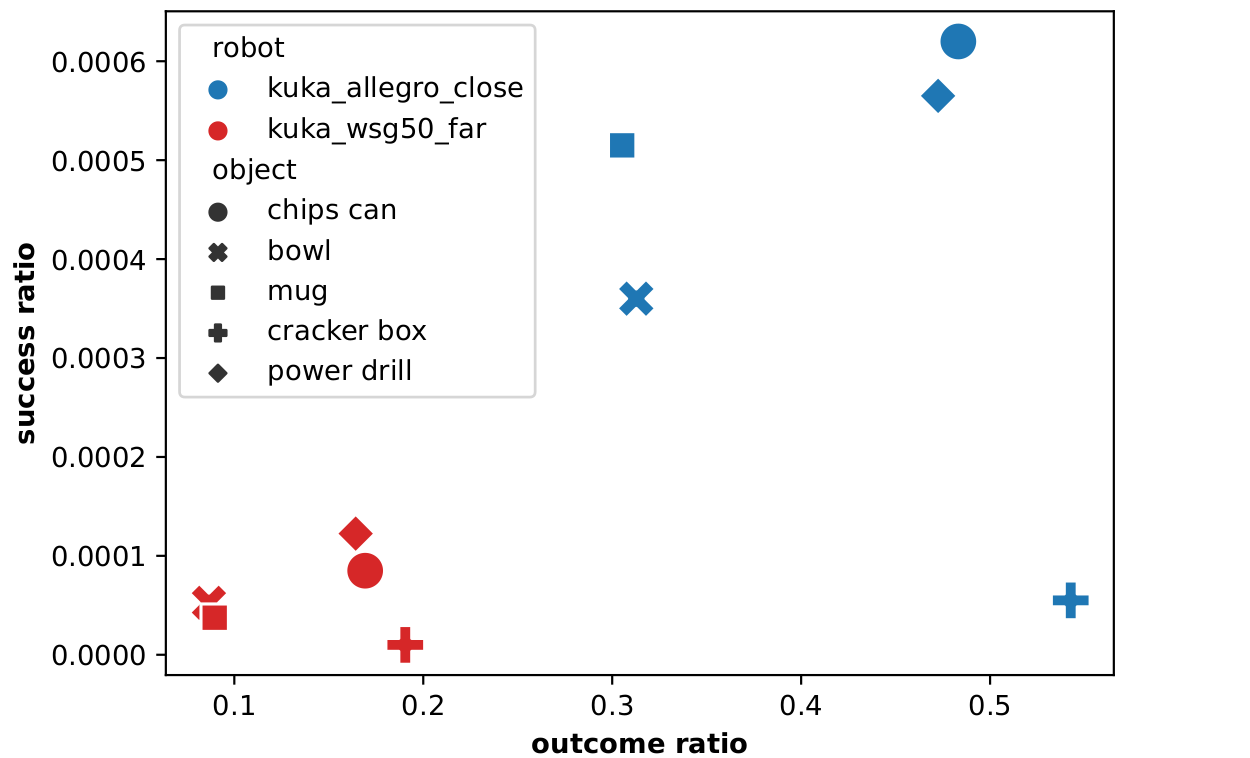
The higher outcome ratios are about 50%, meaning that half of the randomly sampled individuals lead to a grasping attempt that does not even touch the object. Consequently, QD methods that successfully address such domains must be able to conduct the evolutionary process even if a significant part of the evaluated solutions do not provide a defined behavioral signal.
It appears that such a sparsity strongly impacts QD methods performances, leading to unexpected results and properties.
Results
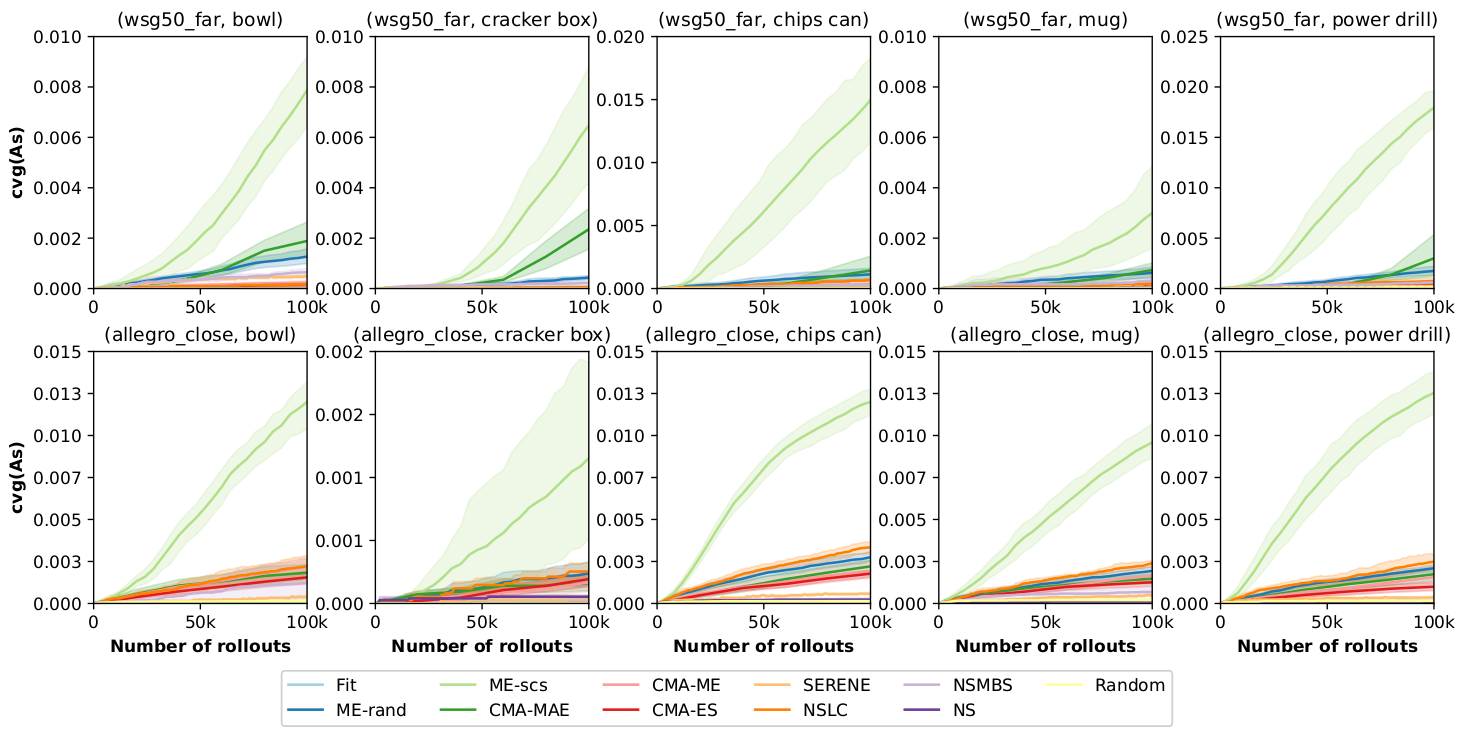
Interestingly, the methods considered the most promising ones for generating diverse and high-performing solutions are dominated by another one by a large margin. This method, ME-scs, is a simple variant of the vanilla MAP-Elites that select previously found successful solutions from the running archive in priority. By doing so, ME-scs focuses the search on previously found solutions, resulting in significantly more discovered diverse successful grasps.

The visualization of both the approach and the position of prehension show that the generated grasps cover the whole operational space. A method as simple as a standard MAP-Elites can, therefore, successfully generate a large set of diverse and high-performing grasping trajectories that can be used as datasets for learning or straightforwardly used on real robots.
Other experiments conducted in the paper investigate the role of the selection operator on QD methods performances on grasping. In particular, one can distinguish success-greedy methods (like ME-scs) from fitness-greedy ones (that select the best-performing solutions in priority). Both dominate state-of-the-art QD methods – including NSMBS, SERENE, and CMA-MAE – but success-greedy methods find more diverse solutions that are slightly less performant. In contrast, fitness-greedy methods find less diverse solutions but can produce grasping trajectories of higher quality.
Conclusions
This work investigates how to address grasping with QD. In particular, it shows that a simple variant of MAP-Elites that focuses on selecting previously found successful grasps results in the generation of a large set of diverse and high-performing grasping trajectories. The significant gap with the compared QD state-of-the-art method shows room for improving QD algorithms to address manipulation tasks like grasping. Nevertheless, the obtained diversity is already enough for producing grasps that can be exploited on real robots.
This blog post does not cover all the paper's contributions. In fact, it appears that facing sparse interaction tasks like grasping results in unexpected properties for standard QD methods, raising questions for upcoming research. Take a look at the paper to read more about it!
Acknowledgement
This work was supported by the Sorbonne Center for Artificial Intelligence, the German Ministry of Education and Research (BMBF) (01IS21080), and the French Agence Nationale de la Recherche (ANR) (ANR-21-FAI1-0004) - Learn2Grasp. It has received funding from the European Commission’s Horizon Europe Framework Programme under grant agreement No 101070381 and from the European Union’s Horizon Europe Framework Programme under grant agreement No 101070596. This work was performed using HPC resources from GENCI-IDRIS (Grant 20XX-AD011014320).
References
Hodson, R. (2018). A gripping problem: designing machines that can grasp and manipulate objects with anything approaching human levels of dexterity is first on the to-do list for robotics. Nature.
Morrison, D., Corke, P., & Leitner, J. (2020). Egad! an evolved grasping analysis dataset for diversity and reproducibility in robotic manipulation. IEEE Robotics and Automation Letters, 5(3), 4368-4375.
Macé, V., Boige, R., Chalumeau, F., Pierrot, T., Richard, G., & Perrin-Gilbert, N. (2023). The Quality-Diversity Transformer: Generating Behavior-Conditioned Trajectories with Decision Transformers. arXiv preprint arXiv:2303.16207.
Mouret, J. B., Clune, J. (2015). Illuminating search spaces by mapping elites. arXiv preprint arXiv:1504.04909.
Cully, A., Clune, J., Tarapore, D., & Mouret, J. B. (2015). Robots that can adapt like animals. Nature, 521(7553), 503-507.
Morel, A., Kunimoto, Y., Coninx, A., Doncieux, S. (2022, May). Automatic acquisition of a repertoire of diverse grasping trajectories through behavior shaping and novelty search. In 2022 International Conference on Robotics and Automation (ICRA) (pp. 755-761). IEEE.
Lehman, J. and Stanley, K. O. (2011). Abandoning objectives: Evolution through the search for novelty alone. Evo. comp., 19(2):189–223.
Fontaine, M. and Nikolaidis, S. (2023). Covariance matrix adaptation map-annealing. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 456–465.
Paolo, G., Coninx, A., Doncieux, S., and Laflaquière, A. (2021). Sparse reward exploration via novelty search and emitters. In Proceedings of the Genetic and Evolutionary Computation Conference, pages 154–162.